Use Cases & Benefits Of Tokenization to Secure Digital Assets
June 7, 2023

What is Consistent Data Tokenization?
When it comes to data security and privacy, one of the best ways to ensure data protection in the cloud is using Tokenization. Usually an irreversible process, it converts data into tokens, which are mapped to the original data stored securely. With various algorithms, this is possible. But, this comes with its share of problems. These algorithms are generally automatic. Due to this, these tokens will be mapped inconsistently, that is, data points with the same feature will be marked differently which may or may not skew the analytics.
To deal with such inconsistencies, the concept of tokenizing data in a consistent manner came up. Providing tokens for features that are consistent and traceable, will remove a lot of the headaches associated with data tokenization and trying to decipher any possible trend.
It is a delicate balance to not only tokenize data in a consistent manner but also hide users’ PII (Personally Identifiable Information) in a safe and secure way. With a structure defined for the tokenization algorithms, it reduces the possibility of loopholes or any existing vulnerabilities it may have had, making the dataset airtight.
Protecto provides state-of-the-art technology with the latest techniques to tokenize your data. They provide agentless services, which means that our tokenization services can be integrated into your cloud infrastructure seamlessly since there are no agents.
Benefits of consistent tokenization
Consistent tokenization helps maintain consistency across different instances of tokenization. This approach offers several benefits:

1. Enhanced Data Security:
Tokenization can be used to replace sensitive data, such as credit card numbers or personally identifiable information (PII), with tokens that have no inherent meaning or value. Consistently tokenizing data ensures that the same piece of information is always replaced with the same token, enabling secure data storage and transmission without exposing sensitive details.
2. Simplified Data Integration:
Consistent tokenization enables easier data integration and interoperability. When different systems or applications tokenize data consistently, they can share and process information seamlessly without confusion or inconsistencies. This simplifies data exchange, data synchronization, and integration efforts between various systems.
3. Improved Privacy and Compliance:
Tokenization aids in achieving compliance with data privacy regulations, such as the General Data Protection Regulation (GDPR). Consistently tokenizing data helps organizations adhere to privacy requirements by reducing the amount of sensitive information they store and process. It also allows for better anonymization and data obfuscation, minimizing the risk of data breaches and unauthorized access.
4. Facilitates Data Analytics:
Tokenization supports data analytics and machine learning initiatives. By consistently tokenizing data, organizations can analyze and derive insights from the tokenized information while preserving the privacy and security of the original data. It enables data scientists and analysts to perform computations, statistical analysis, and predictive modeling without accessing the sensitive data itself.
5. Increased Performance:
Tokenization can improve performance in certain scenarios. When working with large datasets, tokenization reduces the need for complex compliance approvals and security checks, making it faster to process and transmit information. This can lead to improved system performance, and decreased computing requirements.
6. Simplified Testing and Debugging:
Consistent data tokenization can simplify testing and debugging processes. Developers can work with tokenized data during software development and testing stages, eliminating the need for using real sensitive data. This helps prevent accidental exposure of sensitive information and ensures a safer development environment.
7. Scalability and Interchangeability:
Consistent tokenization allows for scalability and interchangeability of systems and components. Since the same data is tokenized consistently across different systems, it becomes easier to replace or upgrade individual components without disrupting the overall data flow. It facilitates system evolution and ensures compatibility during system upgrades or migrations.
Overall, consistent data tokenization provides a range of benefits including improved data security, simplified integration, enhanced privacy and compliance, support for data analytics, increased performance, simplified testing, and scalability. These advantages make consistent data tokenization a valuable technique for organizations handling sensitive information while maintaining operational efficiency.
Importance of Consistent Data Tokenization for Seamless Analytics
The most important use case of data is to predict different trends and give insights about the users of a business. To be able to form insights and perform data analytics without infringing on the user’s privacy is a great challenge. If the data points are not tokenized consistently, that is, similar types of data points having similar tokens will make it easy for machine learning models to detect patterns and have an idea of what the data points mean without knowing any actual information.
Not only that but, user data can have greater security since, consistently tokenizing data will create airtight security preventing any data leaks during transferring, debugging (when data points aren’t assembled correctly) or any system maintenance. Having consistent data through different systems will also enhance the readability of data as when new employees parse through the data, they need not start from the ground up, instead, they can use that time to analyze the data, provide insights, and save precious time.
Data analytics often involves combining data from different sources based on shared attributes or fields. This process is critical as it allows businesses and organizations to derive insights that would have been impossible to obtain from analyzing one data source alone.
By integrating data from multiple sources, analysts can gain a more complete and accurate understanding of the data, identify patterns and trends that would have gone unnoticed, and make informed decisions based on comprehensive and reliable information. Therefore, joining data through common fields is an essential requirement for any data analytics project, enabling organizations to unlock the full potential of their data.
Tokenization and the need for consistent tokens
Tokenization is an approach that is commonly used to protect personal data. Tokenization involves replacing sensitive data with a random value or token that has no meaningful relationship to the original data. The tokenized data can then be stored and processed without revealing the original sensitive data, ensuring that it remains secure.
At the same time, consistent tokens are crucial for seamless analytics, machine learning (ML), and artificial intelligence (AI) because they enable accurate and reliable data analysis, model training, and prediction. When data elements are consistently tokenized across different data sets, it becomes easier to combine and analyze them. This consistency helps to eliminate errors and inaccuracies that could arise from inconsistent or incorrect data identification.
For example, if John Smith's sales data is represented by ten different inconsistent tokens, it would be challenging to summarize his monthly sales accurately. The data analyst would need to identify and aggregate all the different tokens related to John Smith manually, which would be time-consuming and prone to errors. Inconsistent tokens within the same table can also lead to duplicated data and skewed analysis results.
Other factors pushing for consistent tokens include:
-> Need for unique identifiers to join multiple datasets
In most data sets, Personally Identifiable Information (PII) data, such as names, addresses, or social security numbers, is often used as a unique identifier to join multiple data sets. By joining data sets based on common PII fields, we can gain more insights and make informed decisions based on a comprehensive view of the data.
For instance, let's consider a healthcare data scenario where we have one data set containing patient demographic information (such as name, date of birth, and address), another data set containing diagnosis codes for each patient, and yet another data set containing medication history for each patient. By joining these data sets based on the common PII fields (such as name and date of birth), we can get a complete picture of each patient's medical history, including diagnosis, treatment, and medication information.
Similarly, in the financial industry, customer identification numbers (CINs) or social security numbers (SSNs) are often used as unique identifiers to link data from different systems such as customer account information, transaction history, and credit history. By linking these data sets, financial institutions can identify fraud, assess credit risk, and make better decisions about their customers.
Tokens that replace PII data must act as unique identifiers to summarize data sets. Having unique tokens that protect privacy and security is crucial for accurate and comprehensive data analysis.
-> Need for consistency within tables
PII (Personally Identifiable Information) is sensitive data that can identify individuals, such as names, addresses, and social security numbers. To protect the privacy and security of this data, it is often masked with inconsistent tokens, which are random identifiers that replace the original PII values. However, using inconsistent tokens can make it difficult to summarize data as the same individual's data will be spread across different tokens, making it challenging to aggregate and analyze their data effectively.
-> Need for consistency across datasets
When data sets have different inconsistent tokens, it becomes challenging to join them together using a shared attribute or field such as customer email. Inconsistent tokens create a mismatch between the attribute values of the same entity (such as the customer) in different data sets, leading to incorrect or incomplete data analysis results.
For instance, if the customer email field in the customer table uses a different set of inconsistent tokens compared to the order table, it would not be possible to match and join the two tables based on customer email to determine sales by customer location accurately. As a result, the data analyst would not be able to obtain insights into customer behavior across different locations or regions, which could be critical for business decision-making.
Therefore, ensuring consistency in token generation across different data sets is essential for effective data integration and analysis. This consistency enables the accurate matching of the same entity across multiple data sets, leading to a more complete and accurate analysis of the data. It also enables data analysts to join data sets seamlessly, allowing for the derivation of insights that would have been impossible to obtain otherwise.
Also Read: Copy Production Data To Non-prod Without Privacy Or Security Risks
Growing need to protect data privacy
Governments around the world are enacting stricter data protection regulations such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States, which require organizations to take measures to protect personal and sensitive data.
At the same time, security threats such as data breaches and cyberattacks are increasing, with hackers and cybercriminals seeking to gain unauthorized access to sensitive data for financial gain or other malicious purposes. In many cases, personal data is a prime target for hackers, making it critical for organizations to protect this data through effective data security measures.
Overall, the need to protect personal data is becoming increasingly important in today's data-driven world. Organizations are turning to data security measures such as masking, encryption and tokenization to protect sensitive data and comply with data protection regulations, while also safeguarding against security threats and ensuring the privacy of individuals.
Analytics can’t run on masked data
Masking is a technique used to hide sensitive information such as personally identifiable information (PII) by replacing it with non-sensitive data or a mask. Masking is often used to protect the privacy and security of personal data during data processing, storage, and transmission.
However, one of the limitations of masking is that it can limit the usefulness of the data for analytics purposes. When data is masked, the original sensitive data is replaced with a mask, making it impossible to retrieve the original data from the masked data. As a result, masked data may not be suitable for certain types of analytics or data processing that require the use of the original data.
For example, if a company needs to analyze customer purchase history to identify trends and patterns, masking the customer names or other PII may limit the usefulness of the data for this purpose. Similarly, if a healthcare provider needs to analyze patient data to identify health trends, masking patient names or other PII may limit the usefulness of the data for this purpose.
To address this limitation, there are other techniques such as tokenization that can be used to protect personal data while still allowing for useful analytics. Tokenization replaces sensitive data with tokens, which can be used to perform analytics without revealing the original data.
In summary, while masking is an effective technique for protecting the privacy and security of personal data, it can limit the usefulness of the data for analytics purposes. Tokenization can be used to address this limitation and still allow for useful analytics while protecting personal data.
Interesting Read: How Data Tokenization Plays an Effective Role in Data Security
Top use cases of Consistent Data Tokenization
Due to its many advantages, Consistent Data Tokenization is used in many real-life scenarios and complex use cases. Here are some of them explained to you in detail.
Blockchain Tokenization

When it comes to using non-fungible data points to keep a record permanent, Blockchain is used. The same data is shown to multiple people to add new data points and view it. To improve the security of data stored using blockchain, these blockchains can be subject to tokenization. In this case, using Non-Fungible Tokens (NFTs) may be convenient, but, to protect the NFT, there is a need for consistent data tokenization so that the blockchain provider may not be able to see their user’s NFT account used for transactions using blockchain (using Algorand, Bitcoin, etc).
e-Commerce Tokenization

In this day and age, many new e-commerce sites are coming up serving a unique niche. Gone are the days when mega-corporations such as Amazon, Google, and so on were the only e-commerce sites available. With new businesses popping up every day, there is much more data generated from the users. With growing concerns for privacy laws in cyberspace, the consensus is to mask the original data, that is, pseudonymize and sanitize the data. E-commerce businesses can tokenize their user’s data and tokenize it in a way that is able to show the data handlers a vague idea of the data type and what they’re dealing with.
Credit Card Tokenization

When you do a bank transfer, sometimes, you use your credit card to pay for something. Your credit card holds valuable information and has a limit on the amount of money you can spend. Secret numbers such as your CVV and credit card numbers cannot be known to anyone, not even your credit card providers. To ensure the maximum amount of data privacy, the providers can tokenize all the data of the user. But, to properly identify the user, and to view their credit score, they would require some data from the card. To not infringe on the user’s privacy and view their private information, their credit transaction details will be tokenized in a specific way to signal those in the credit card company about the credit score the particular user may possess.
Payment Tokenization
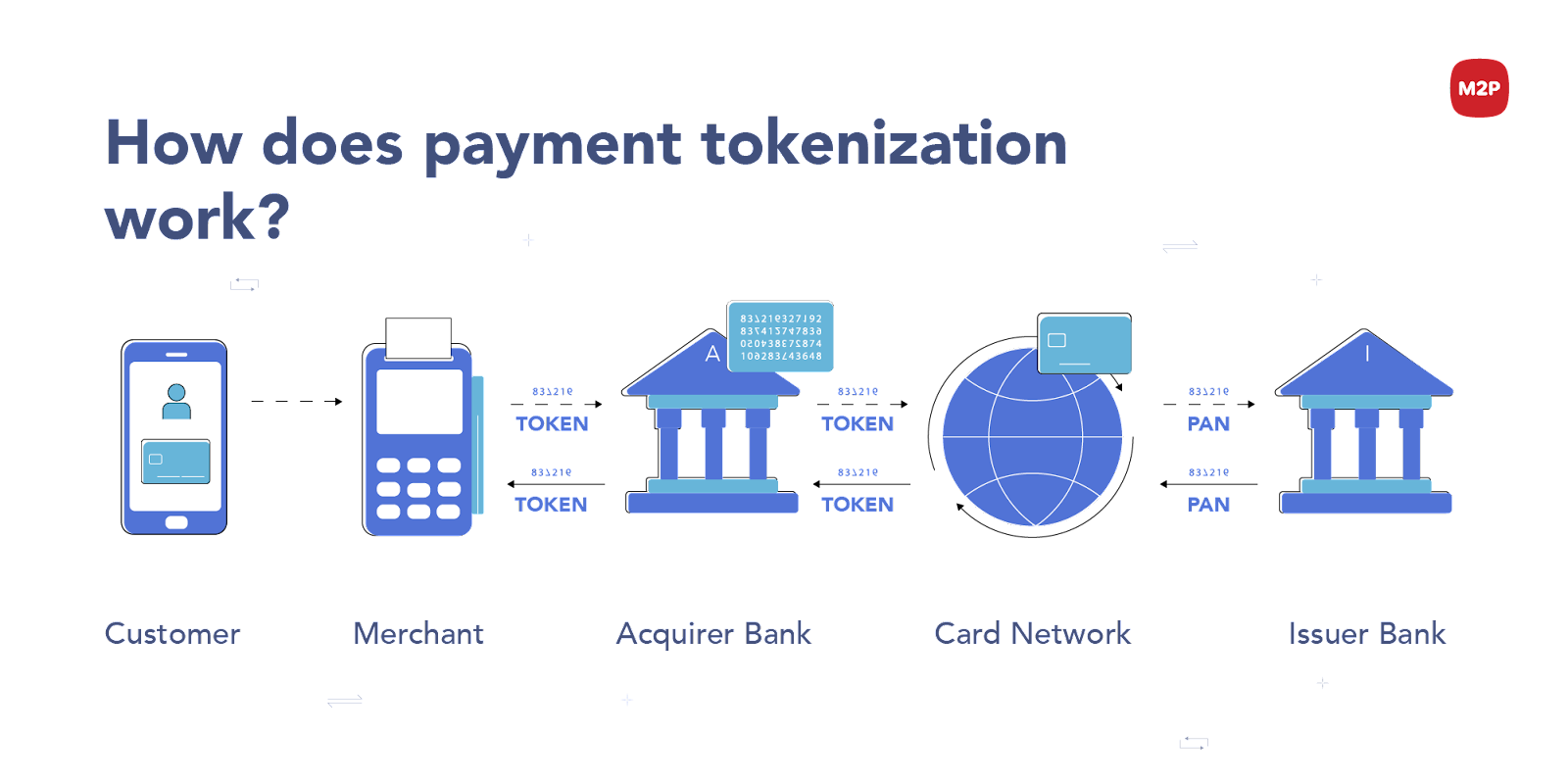
In the digital age, it has given rise to many ways to construct digital payment portals through which, payments and transactions can be made, be it through blockchain (Ethereum transactions), or paying through PayPal or GPay. Such transactions must be recorded somewhere and can be viewed only by the user. This data is generally tokenized to prevent unwanted people from viewing your payment transactions. With consistent tokenization, your name and ID will remain consistent throughout the different payment portals you use to send money. By tokenising your name and account type, your transactions can be viewed and the appropriate amount can be cut from your account for every transaction made by you.
The Protecto advantage
Protecto's advanced tokenization technology is designed to ensure that data elements are consistently and uniquely tokenized, making it easier to analyze and combine data sets. The advanced tokenization algorithm is designed to identify specific patterns within the data elements and generate tokens that closely maintain form. This ensures that even if the same data element appears in different data sets, it will always be tokenized in the same way, making it easier to combine and analyze data across different data sources.
Protecto's intelligent tokenization technology also includes advanced algorithms that enable it to identify personal data and attach the right tokens across different data sets accurately.
If you want to witness how effortless it is to implement data access control with Protecto, try Protecto for FREE today by requesting a trial.
Suggested Read: All You Need To Know About Data Privacy
Frequently Asked Questions
What is data tokenization?
Data tokenization is the process of replacing sensitive data elements, such as credit card numbers or personally identifiable information (PII), with unique identification symbols called tokens. These tokens are randomly generated and hold no meaningful information, ensuring the original data is protected.
Why is consistent data tokenization important?
Consistent data tokenization is important for maintaining data privacy, security, and integrity across different systems and processes. It ensures that the same data elements are consistently represented by the same tokens, allowing for seamless data integration and analysis.
How does consistent data tokenization enhance data security?
By consistently tokenizing sensitive data, organizations can reduce the risk of exposing sensitive information during storage, transmission, or analysis. Tokens hold no meaningful value and are useless to potential attackers, providing an extra layer of security.
What role does consistent data tokenization play in regulatory compliance?
Many data protection regulations, such as GDPR or PCI DSS, require organizations to implement strong data protection measures. Consistent data tokenization helps organizations comply with these regulations by minimizing the storage and processing of sensitive data, reducing the risk of non-compliance.
How does consistent data tokenization enable seamless data integration?
Consistent tokenization ensures that data from different sources can be easily integrated without the need to handle sensitive information. Tokens act as placeholders for the original data, allowing for smooth data integration and analysis across multiple systems or applications.
Does consistent data tokenization impact data analytics accuracy?
Consistent data tokenization should not impact data analytics accuracy when properly implemented. The tokens retain the essential characteristics of the original data, allowing for accurate analysis and reporting without revealing sensitive information.
Can tokenization be applied to all types of sensitive data?
Tokenization can be applied to various types of sensitive data, including credit card numbers, personally identifiable information (PII), social security numbers, and more. However, the feasibility and appropriateness of tokenization for specific data types should be evaluated based on security, regulatory, and business requirements.
What is Consistent Data Tokenization?
When it comes to data security and privacy, one of the best ways to ensure data protection in the cloud is using Tokenization. Usually an irreversible process, it converts data into tokens, which are mapped to the original data stored securely. With various algorithms, this is possible. But, this comes with its share of problems. These algorithms are generally automatic. Due to this, these tokens will be mapped inconsistently, that is, data points with the same feature will be marked differently which may or may not skew the analytics.
To deal with such inconsistencies, the concept of tokenizing data in a consistent manner came up. Providing tokens for features that are consistent and traceable, will remove a lot of the headaches associated with data tokenization and trying to decipher any possible trend.
It is a delicate balance to not only tokenize data in a consistent manner but also hide users’ PII (Personally Identifiable Information) in a safe and secure way. With a structure defined for the tokenization algorithms, it reduces the possibility of loopholes or any existing vulnerabilities it may have had, making the dataset airtight.
Protecto provides state-of-the-art technology with the latest techniques to tokenize your data. They provide agentless services, which means that our tokenization services can be integrated into your cloud infrastructure seamlessly since there are no agents.
Benefits of consistent tokenization
Consistent tokenization helps maintain consistency across different instances of tokenization. This approach offers several benefits:
1. Enhanced Data Security:
Tokenization can be used to replace sensitive data, such as credit card numbers or personally identifiable information (PII), with tokens that have no inherent meaning or value. Consistently tokenizing data ensures that the same piece of information is always replaced with the same token, enabling secure data storage and transmission without exposing sensitive details.
2. Simplified Data Integration:
Consistent tokenization enables easier data integration and interoperability. When different systems or applications tokenize data consistently, they can share and process information seamlessly without confusion or inconsistencies. This simplifies data exchange, data synchronization, and integration efforts between various systems.
3. Improved Privacy and Compliance:
Tokenization aids in achieving compliance with data privacy regulations, such as the General Data Protection Regulation (GDPR). Consistently tokenizing data helps organizations adhere to privacy requirements by reducing the amount of sensitive information they store and process. It also allows for better anonymization and data obfuscation, minimizing the risk of data breaches and unauthorized access.
4. Facilitates Data Analytics:
Tokenization supports data analytics and machine learning initiatives. By consistently tokenizing data, organizations can analyze and derive insights from the tokenized information while preserving the privacy and security of the original data. It enables data scientists and analysts to perform computations, statistical analysis, and predictive modeling without accessing the sensitive data itself.
5. Increased Performance:
Tokenization can improve performance in certain scenarios. When working with large datasets, tokenization reduces the need for complex compliance approvals and security checks, making it faster to process and transmit information. This can lead to improved system performance, and decreased computing requirements.
6. Simplified Testing and Debugging:
Consistent data tokenization can simplify testing and debugging processes. Developers can work with tokenized data during software development and testing stages, eliminating the need for using real sensitive data. This helps prevent accidental exposure of sensitive information and ensures a safer development environment.
7. Scalability and Interchangeability:
Consistent tokenization allows for scalability and interchangeability of systems and components. Since the same data is tokenized consistently across different systems, it becomes easier to replace or upgrade individual components without disrupting the overall data flow. It facilitates system evolution and ensures compatibility during system upgrades or migrations.
Overall, consistent data tokenization provides a range of benefits including improved data security, simplified integration, enhanced privacy and compliance, support for data analytics, increased performance, simplified testing, and scalability. These advantages make consistent data tokenization a valuable technique for organizations handling sensitive information while maintaining operational efficiency.
Importance of Consistent Data Tokenization for Seamless Analytics
The most important use case of data is to predict different trends and give insights about the users of a business. To be able to form insights and perform data analytics without infringing on the user’s privacy is a great challenge. If the data points are not tokenized consistently, that is, similar types of data points having similar tokens will make it easy for machine learning models to detect patterns and have an idea of what the data points mean without knowing any actual information.
Not only that but, user data can have greater security since, consistently tokenizing data will create airtight security preventing any data leaks during transferring, debugging (when data points aren’t assembled correctly) or any system maintenance. Having consistent data through different systems will also enhance the readability of data as when new employees parse through the data, they need not start from the ground up, instead, they can use that time to analyze the data, provide insights, and save precious time.
Data analytics often involves combining data from different sources based on shared attributes or fields. This process is critical as it allows businesses and organizations to derive insights that would have been impossible to obtain from analyzing one data source alone.
By integrating data from multiple sources, analysts can gain a more complete and accurate understanding of the data, identify patterns and trends that would have gone unnoticed, and make informed decisions based on comprehensive and reliable information. Therefore, joining data through common fields is an essential requirement for any data analytics project, enabling organizations to unlock the full potential of their data.
Tokenization and the need for consistent tokens
Tokenization is an approach that is commonly used to protect personal data. Tokenization involves replacing sensitive data with a random value or token that has no meaningful relationship to the original data. The tokenized data can then be stored and processed without revealing the original sensitive data, ensuring that it remains secure.
At the same time, consistent tokens are crucial for seamless analytics, machine learning (ML), and artificial intelligence (AI) because they enable accurate and reliable data analysis, model training, and prediction. When data elements are consistently tokenized across different data sets, it becomes easier to combine and analyze them. This consistency helps to eliminate errors and inaccuracies that could arise from inconsistent or incorrect data identification.
For example, if John Smith's sales data is represented by ten different inconsistent tokens, it would be challenging to summarize his monthly sales accurately. The data analyst would need to identify and aggregate all the different tokens related to John Smith manually, which would be time-consuming and prone to errors. Inconsistent tokens within the same table can also lead to duplicated data and skewed analysis results.
Other factors pushing for consistent tokens include:
-> Need for unique identifiers to join multiple datasets
In most data sets, Personally Identifiable Information (PII) data, such as names, addresses, or social security numbers, is often used as a unique identifier to join multiple data sets. By joining data sets based on common PII fields, we can gain more insights and make informed decisions based on a comprehensive view of the data.
For instance, let's consider a healthcare data scenario where we have one data set containing patient demographic information (such as name, date of birth, and address), another data set containing diagnosis codes for each patient, and yet another data set containing medication history for each patient. By joining these data sets based on the common PII fields (such as name and date of birth), we can get a complete picture of each patient's medical history, including diagnosis, treatment, and medication information.
Similarly, in the financial industry, customer identification numbers (CINs) or social security numbers (SSNs) are often used as unique identifiers to link data from different systems such as customer account information, transaction history, and credit history. By linking these data sets, financial institutions can identify fraud, assess credit risk, and make better decisions about their customers.
Tokens that replace PII data must act as unique identifiers to summarize data sets. Having unique tokens that protect privacy and security is crucial for accurate and comprehensive data analysis.
-> Need for consistency within tables
PII (Personally Identifiable Information) is sensitive data that can identify individuals, such as names, addresses, and social security numbers. To protect the privacy and security of this data, it is often masked with inconsistent tokens, which are random identifiers that replace the original PII values. However, using inconsistent tokens can make it difficult to summarize data as the same individual's data will be spread across different tokens, making it challenging to aggregate and analyze their data effectively.
-> Need for consistency across datasets
When data sets have different inconsistent tokens, it becomes challenging to join them together using a shared attribute or field such as customer email. Inconsistent tokens create a mismatch between the attribute values of the same entity (such as the customer) in different data sets, leading to incorrect or incomplete data analysis results.
For instance, if the customer email field in the customer table uses a different set of inconsistent tokens compared to the order table, it would not be possible to match and join the two tables based on customer email to determine sales by customer location accurately. As a result, the data analyst would not be able to obtain insights into customer behavior across different locations or regions, which could be critical for business decision-making.
Therefore, ensuring consistency in token generation across different data sets is essential for effective data integration and analysis. This consistency enables the accurate matching of the same entity across multiple data sets, leading to a more complete and accurate analysis of the data. It also enables data analysts to join data sets seamlessly, allowing for the derivation of insights that would have been impossible to obtain otherwise.
Also Read: Copy Production Data To Non-prod Without Privacy Or Security Risks
Growing need to protect data privacy
Governments around the world are enacting stricter data protection regulations such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States, which require organizations to take measures to protect personal and sensitive data.
At the same time, security threats such as data breaches and cyberattacks are increasing, with hackers and cybercriminals seeking to gain unauthorized access to sensitive data for financial gain or other malicious purposes. In many cases, personal data is a prime target for hackers, making it critical for organizations to protect this data through effective data security measures.
Overall, the need to protect personal data is becoming increasingly important in today's data-driven world. Organizations are turning to data security measures such as masking, encryption and tokenization to protect sensitive data and comply with data protection regulations, while also safeguarding against security threats and ensuring the privacy of individuals.
Analytics can’t run on masked data
Masking is a technique used to hide sensitive information such as personally identifiable information (PII) by replacing it with non-sensitive data or a mask. Masking is often used to protect the privacy and security of personal data during data processing, storage, and transmission.
However, one of the limitations of masking is that it can limit the usefulness of the data for analytics purposes. When data is masked, the original sensitive data is replaced with a mask, making it impossible to retrieve the original data from the masked data. As a result, masked data may not be suitable for certain types of analytics or data processing that require the use of the original data.
For example, if a company needs to analyze customer purchase history to identify trends and patterns, masking the customer names or other PII may limit the usefulness of the data for this purpose. Similarly, if a healthcare provider needs to analyze patient data to identify health trends, masking patient names or other PII may limit the usefulness of the data for this purpose.
To address this limitation, there are other techniques such as tokenization that can be used to protect personal data while still allowing for useful analytics. Tokenization replaces sensitive data with tokens, which can be used to perform analytics without revealing the original data.
In summary, while masking is an effective technique for protecting the privacy and security of personal data, it can limit the usefulness of the data for analytics purposes. Tokenization can be used to address this limitation and still allow for useful analytics while protecting personal data.
Interesting Read: How Data Tokenization Plays an Effective Role in Data Security
Top use cases of Consistent Data Tokenization
Due to its many advantages, Consistent Data Tokenization is used in many real-life scenarios and complex use cases. Here are some of them explained to you in detail.
Blockchain Tokenization
When it comes to using non-fungible data points to keep a record permanent, Blockchain is used. The same data is shown to multiple people to add new data points and view it. To improve the security of data stored using blockchain, these blockchains can be subject to tokenization. In this case, using Non-Fungible Tokens (NFTs) may be convenient, but, to protect the NFT, there is a need for consistent data tokenization so that the blockchain provider may not be able to see their user’s NFT account used for transactions using blockchain (using Algorand, Bitcoin, etc).
e-Commerce Tokenization
In this day and age, many new e-commerce sites are coming up serving a unique niche. Gone are the days when mega-corporations such as Amazon, Google, and so on were the only e-commerce sites available. With new businesses popping up every day, there is much more data generated from the users. With growing concerns for privacy laws in cyberspace, the consensus is to mask the original data, that is, pseudonymize and sanitize the data. E-commerce businesses can tokenize their user’s data and tokenize it in a way that is able to show the data handlers a vague idea of the data type and what they’re dealing with.
Credit Card Tokenization
When you do a bank transfer, sometimes, you use your credit card to pay for something. Your credit card holds valuable information and has a limit on the amount of money you can spend. Secret numbers such as your CVV and credit card numbers cannot be known to anyone, not even your credit card providers. To ensure the maximum amount of data privacy, the providers can tokenize all the data of the user. But, to properly identify the user, and to view their credit score, they would require some data from the card. To not infringe on the user’s privacy and view their private information, their credit transaction details will be tokenized in a specific way to signal those in the credit card company about the credit score the particular user may possess.
Payment Tokenization
In the digital age, it has given rise to many ways to construct digital payment portals through which, payments and transactions can be made, be it through blockchain (Ethereum transactions), or paying through PayPal or GPay. Such transactions must be recorded somewhere and can be viewed only by the user. This data is generally tokenized to prevent unwanted people from viewing your payment transactions. With consistent tokenization, your name and ID will remain consistent throughout the different payment portals you use to send money. By tokenising your name and account type, your transactions can be viewed and the appropriate amount can be cut from your account for every transaction made by you.
The Protecto advantage
Protecto's advanced tokenization technology is designed to ensure that data elements are consistently and uniquely tokenized, making it easier to analyze and combine data sets. The advanced tokenization algorithm is designed to identify specific patterns within the data elements and generate tokens that closely maintain form. This ensures that even if the same data element appears in different data sets, it will always be tokenized in the same way, making it easier to combine and analyze data across different data sources.
Protecto's intelligent tokenization technology also includes advanced algorithms that enable it to identify personal data and attach the right tokens across different data sets accurately.
If you want to witness how effortless it is to implement data access control with Protecto, try Protecto for FREE today by requesting a trial.
Suggested Read: All You Need To Know About Data Privacy
Frequently Asked Questions
What is data tokenization?
Data tokenization is the process of replacing sensitive data elements, such as credit card numbers or personally identifiable information (PII), with unique identification symbols called tokens. These tokens are randomly generated and hold no meaningful information, ensuring the original data is protected.
Why is consistent data tokenization important?
Consistent data tokenization is important for maintaining data privacy, security, and integrity across different systems and processes. It ensures that the same data elements are consistently represented by the same tokens, allowing for seamless data integration and analysis.
How does consistent data tokenization enhance data security?
By consistently tokenizing sensitive data, organizations can reduce the risk of exposing sensitive information during storage, transmission, or analysis. Tokens hold no meaningful value and are useless to potential attackers, providing an extra layer of security.
What role does consistent data tokenization play in regulatory compliance?
Many data protection regulations, such as GDPR or PCI DSS, require organizations to implement strong data protection measures. Consistent data tokenization helps organizations comply with these regulations by minimizing the storage and processing of sensitive data, reducing the risk of non-compliance.
How does consistent data tokenization enable seamless data integration?
Consistent tokenization ensures that data from different sources can be easily integrated without the need to handle sensitive information. Tokens act as placeholders for the original data, allowing for smooth data integration and analysis across multiple systems or applications.
Does consistent data tokenization impact data analytics accuracy?
Consistent data tokenization should not impact data analytics accuracy when properly implemented. The tokens retain the essential characteristics of the original data, allowing for accurate analysis and reporting without revealing sensitive information.
Can tokenization be applied to all types of sensitive data?
Tokenization can be applied to various types of sensitive data, including credit card numbers, personally identifiable information (PII), social security numbers, and more. However, the feasibility and appropriateness of tokenization for specific data types should be evaluated based on security, regulatory, and business requirements.

Prevent millions of $ of privacy risks. Learn how.
We take privacy seriously. While we promise not to sell your personal data, we may send product and company updates periodically. You can opt-out or make changes to our communication updates at any time.


