How Open-Source AI is Driving Dramatic Increase in AI Adoption
August 11, 2023

Over the years, open-source AI has witnessed an impressive surge in adoption and acceptance. In the domain of generative AI, open-source frameworks and libraries have emerged as indispensable resources for researchers, developers, and enthusiasts alike.
Before the democratization of AI (which refers to the wider accessibility and availability of AI technologies to a broader audience), AI was primarily utilized by a limited number of large organizations, research institutions, and well-funded companies.
Research and Academia:
AI research began in the 1950s, and during the early years, it was primarily an academic pursuit. Researchers and scientists focused on developing foundational AI algorithms and theories. The field was highly specialized, and access to AI resources was restricted to academic institutions and well-funded research laboratories.
Large Corporations:
Some large corporations, especially those in industries with significant computational requirements, could afford to invest in AI research and development. For example, companies in aerospace, defense, and financial sectors used AI for complex simulations, data analysis, and optimization.
Government and Defense:
Governments, particularly those with substantial military and defense interests, had a significant role in early AI development. AI was explored for military applications, including autonomous vehicles, surveillance, and strategic planning.
Natural Language Processing:
Before democratization, Natural Language Processing (NLP) applications were limited to specialized research and proprietary systems used by corporations and governments. NLP was mostly employed for specific tasks like machine translation and speech recognition.
Robotics:
Robotics research was an early domain of AI, and it was largely conducted in academic and industrial research labs. Advanced robotics systems were used in manufacturing and some specialized industries, but they were expensive and required significant expertise to operate.
Expert Systems:
Expert systems, a form of AI that emulates human expertise in specific domains, were used in some corporate settings. These systems were often expensive to develop and maintain, restricting their use to well-funded organizations.
Medical Diagnosis:
AI was experimented with in medical diagnostics and analysis, but its use was limited due to data availability and computational constraints. Medical AI applications were mainly confined to research labs and well-funded healthcare institutions.
Speech Recognition:
Speech recognition systems were used in certain applications, such as telephone-based customer support systems, but their accuracy and performance were relatively limited compared to today's standards.
In this article, let us understand how the democratization of AI has the potential to solve emerging data privacy challenges.
Democratization of AI
The rise in democratization of AI has been drastic. Here are some Key statistics:
- The global AI market value is expected to reach $267 billion by 2027.
- AI is expected to contribute $15.7 trillion to the global economy by 2030.
- 37% of businesses and organizations employ AI.
- Nine out of ten leading businesses have investments in AI technologies, but less than 15% deploy AI capabilities in their work.
- The rise of AI will eliminate 85 million jobs and create 97 million new ones by 2025.
- The number of AI-based voice assistants, which was around 3 billion in 2020, is projected to rise to 8 billion by the end of 2023. According to a report by Grand View Research, the global market for AI-based voice assistants is expected to grow from $4.4 billion in 2020 to $30.8 billion by 2027.
The democratization of generative AI models owes much to the contribution of open-source frameworks, libraries, and datasets. These valuable resources have served as a fundamental pillar, empowering developers to explore, experiment, and build their AI applications.
By providing pre-trained models and open-source datasets, these tools break down barriers of limited resources and data, making AI accessible to a broader audience. As a result, more individuals can now participate in the AI landscape, fostering innovation and creativity across various fields.
The current excitement surrounding generative AI arises from the ease of use of new user interfaces that allow users to generate high-quality text, graphics, and videos within seconds. Also, the dynamic progress of open-source software has been nothing short of remarkable.
2020
In February 2020, Microsoft introduced its Turing Natural Language Generation (T-NLG), which was then the "largest language model ever published at 17 billion parameters.
OpenAI's GPT-3, a state-of-the-art autoregressive language model that uses deep learning to produce a variety of computer codes, poetry and other language tasks exceptionally similar, and almost indistinguishable from those written by humans. Its capacity was ten times greater than that of the T-NLG. It was introduced in May 2020, and was in beta testing in June 2020.
2022
ChatGPT, an AI chatbot developed by OpenAI, debuts in November 2022. It is initially built on top of the GPT-3.5 large language model. While it gains considerable praise for the breadth of its knowledge base, deductive abilities, and the human-like fluidity of its natural language responses, it also garners criticism for, among other things, its tendency to "hallucinate.", a phenomenon in which an AI responds with factually incorrect answers with high confidence. The release triggers widespread public discussion on artificial intelligence and its potential impact on society.
2023
By January 2023, ChatGPT has more than 100 million users, making it the fastest growing consumer application to date.
OpenAI's GPT-4 model is released in March 2023 and is regarded as an impressive improvement over GPT-3.5, with the caveat that GPT-4 retains many of the same problems of the earlier iteration. Unlike previous iterations, GPT-4 is multimodal, allowing image input as well as text. GPT-4 is integrated into ChatGPT as a subscriber service. OpenAI claims that in their own testing the model received a score of 1410 on the SAT (94th percentile),163 on the LSAT (88th percentile), and 298 on the Uniform Bar Exam (90th percentile).
In response to ChatGPT, Google releases in a limited capacity its chatbot Google Bard, based on the LaMDA and PaLM large language models, in March 2023.In May 2023, Google made an announcement regarding Bard's transition from LaMDA to PaLM2, a significantly more advanced language model.
(Source: Wikipedia)
Challenges in the Wake of Opportunities
The adoption of OpenAI and other AI technologies presents several challenges, especially concerning data privacy issues. Here are some of the key challenges related to data privacy when adopting OpenAI or similar AI systems:
Risks Associated with Training Data
The accidental leakage of personally identifiable information (PII) during data inputs for training and prompts in AI models poses a serious threat to data privacy and security. PII includes sensitive information such as names, addresses, contact details, and even financial or medical records, which, if exposed, could lead to identity theft, fraud, or other malicious activities.
As AI models are often trained on vast datasets that may contain PII, there is a risk of unintentionally incorporating this information into the model's learned patterns. Additionally, prompts used to interact with AI models could inadvertently expose PII, further exacerbating the issue. To safeguard against such risks, rigorous data anonymization and de-identification techniques must be employed during the training process, and AI developers and users need to be vigilant about the information they share to protect individuals' privacy and maintain the integrity of AI systems.
Data Access Controls
Data access controls are particularly challenging for AI due to several reasons.
- Firstly, AI models typically require large volumes of diverse data for effective training and performance. This extensive data requirement necessitates access to a wide range of datasets, some of which may contain sensitive or personal information. Ensuring access only to authorized and relevant data is a complex task.
- Secondly, AI models often operate on cloud-based platforms or distributed environments, making it difficult to track and control data access across multiple locations and systems. The data may reside in various databases, and maintaining consistent access controls can become unwieldy.
- Furthermore, AI models tend to learn and improve iteratively by continuously ingesting new data, which can further complicate access control mechanisms. Striking a balance between enabling AI models to learn from fresh data and ensuring data privacy can be quite challenging.
- Finally, AI systems can be vulnerable to attacks targeting data poisoning or adversarial inputs. In such scenarios, controlling data access becomes crucial to prevent malicious data from influencing the model's behavior.
To address these challenges, robust data governance frameworks, access control policies, and data masking techniques like data tokenization must be employed. Implementing such methods can help safeguard sensitive data while still allowing AI models to make meaningful inferences.
Collaboration between AI developers, data scientists, and data owners is essential to establish effective data access controls that prioritize privacy and security while promoting AI advancements. Organizations must prioritize data protection, implement robust security measures, and be transparent with users about data usage and AI model capabilities.
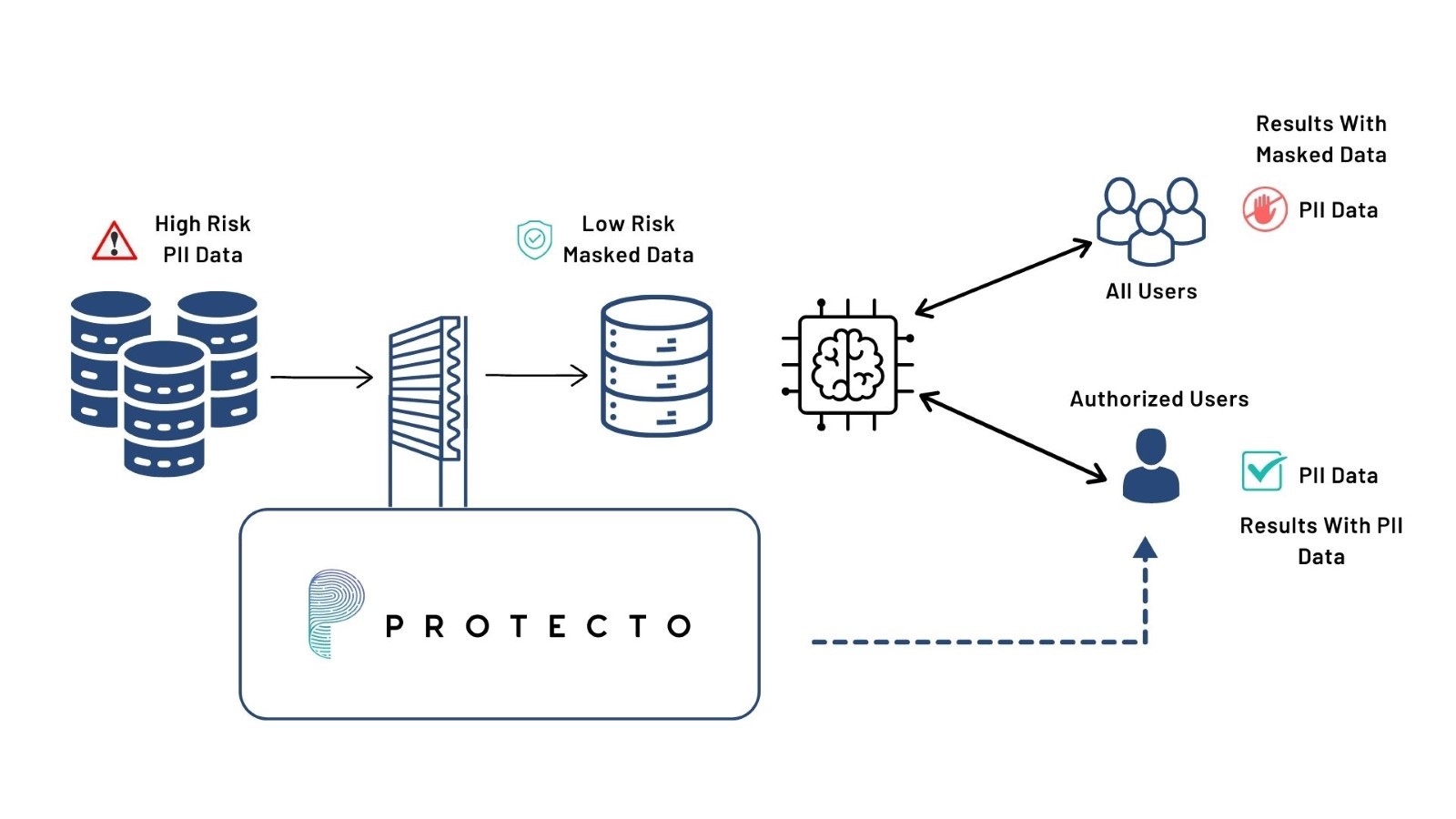
Protecto's Intelligent Data Tokenization Solution
Protecto offers intelligent tokenization to ensure that sanitized data remains machine-readable, enabling companies to harness data-driven insights, predictive analytics, and advanced automation from AI. Using tokenization, companies can leverage the full potential of AI while ensuring privacy and data security.
Here's how Protecto’s Intelligent Tokenization works:
- Input Data Masking:
Protecto masks sensitive data, including PII, before the data is received by the LLM AI system. The data is transformed into a tokenized format, making it incomprehensible and inaccessible to anyone without the necessary permissions.
- Model Training:
The LLM AI model is then trained on the masked data. It learns to understand and process the tokenized information without compromising the original PII.
- Responses with Masked PII:
Since training data was masked before feeding to LLM, during regular interactions with users, none of the responses from the LLM AI will have PII or sensitive data. This means that sensitive information is never exposed to any user without the user having granted explicit permission to access it.
- Controlled Unmasking:
For users who are authorized to access PII, Protecto handles unmasking securely. Only those with proper credentials or permissions can view the original, unmasked PII in the responses from the LLM AI.
Enterprises can confidently adopt AI technologies without worrying about data breaches or accidental leaks. Leverage intelligent tokenization to provide an extra layer of security and protection for your sensitive and personal data.
If your organization is leveraging LLM AI system, and you are worried about how you can protect your personal and sensitive data then schedule a demo or sign up for a free trial today to learn how Protecto can mitigate your privacy and data security risks.
Over the years, open-source AI has witnessed an impressive surge in adoption and acceptance. In the domain of generative AI, open-source frameworks and libraries have emerged as indispensable resources for researchers, developers, and enthusiasts alike.
Before the democratization of AI (which refers to the wider accessibility and availability of AI technologies to a broader audience), AI was primarily utilized by a limited number of large organizations, research institutions, and well-funded companies.
Research and Academia:
AI research began in the 1950s, and during the early years, it was primarily an academic pursuit. Researchers and scientists focused on developing foundational AI algorithms and theories. The field was highly specialized, and access to AI resources was restricted to academic institutions and well-funded research laboratories.
Large Corporations:
Some large corporations, especially those in industries with significant computational requirements, could afford to invest in AI research and development. For example, companies in aerospace, defense, and financial sectors used AI for complex simulations, data analysis, and optimization.
Government and Defense:
Governments, particularly those with substantial military and defense interests, had a significant role in early AI development. AI was explored for military applications, including autonomous vehicles, surveillance, and strategic planning.
Natural Language Processing:
Before democratization, Natural Language Processing (NLP) applications were limited to specialized research and proprietary systems used by corporations and governments. NLP was mostly employed for specific tasks like machine translation and speech recognition.
Robotics:
Robotics research was an early domain of AI, and it was largely conducted in academic and industrial research labs. Advanced robotics systems were used in manufacturing and some specialized industries, but they were expensive and required significant expertise to operate.
Expert Systems:
Expert systems, a form of AI that emulates human expertise in specific domains, were used in some corporate settings. These systems were often expensive to develop and maintain, restricting their use to well-funded organizations.
Medical Diagnosis:
AI was experimented with in medical diagnostics and analysis, but its use was limited due to data availability and computational constraints. Medical AI applications were mainly confined to research labs and well-funded healthcare institutions.
Speech Recognition:
Speech recognition systems were used in certain applications, such as telephone-based customer support systems, but their accuracy and performance were relatively limited compared to today's standards.
In this article, let us understand how the democratization of AI has the potential to solve emerging data privacy challenges.
Democratization of AI
The rise in democratization of AI has been drastic. Here are some Key statistics:
- The global AI market value is expected to reach $267 billion by 2027.
- AI is expected to contribute $15.7 trillion to the global economy by 2030.
- 37% of businesses and organizations employ AI.
- Nine out of ten leading businesses have investments in AI technologies, but less than 15% deploy AI capabilities in their work.
- The rise of AI will eliminate 85 million jobs and create 97 million new ones by 2025.
- The number of AI-based voice assistants, which was around 3 billion in 2020, is projected to rise to 8 billion by the end of 2023. According to a report by Grand View Research, the global market for AI-based voice assistants is expected to grow from $4.4 billion in 2020 to $30.8 billion by 2027.
The democratization of generative AI models owes much to the contribution of open-source frameworks, libraries, and datasets. These valuable resources have served as a fundamental pillar, empowering developers to explore, experiment, and build their AI applications.
By providing pre-trained models and open-source datasets, these tools break down barriers of limited resources and data, making AI accessible to a broader audience. As a result, more individuals can now participate in the AI landscape, fostering innovation and creativity across various fields.
The current excitement surrounding generative AI arises from the ease of use of new user interfaces that allow users to generate high-quality text, graphics, and videos within seconds. Also, the dynamic progress of open-source software has been nothing short of remarkable.
2020
In February 2020, Microsoft introduced its Turing Natural Language Generation (T-NLG), which was then the "largest language model ever published at 17 billion parameters.
OpenAI's GPT-3, a state-of-the-art autoregressive language model that uses deep learning to produce a variety of computer codes, poetry and other language tasks exceptionally similar, and almost indistinguishable from those written by humans. Its capacity was ten times greater than that of the T-NLG. It was introduced in May 2020, and was in beta testing in June 2020.
2022
ChatGPT, an AI chatbot developed by OpenAI, debuts in November 2022. It is initially built on top of the GPT-3.5 large language model. While it gains considerable praise for the breadth of its knowledge base, deductive abilities, and the human-like fluidity of its natural language responses, it also garners criticism for, among other things, its tendency to "hallucinate.", a phenomenon in which an AI responds with factually incorrect answers with high confidence. The release triggers widespread public discussion on artificial intelligence and its potential impact on society.
2023
By January 2023, ChatGPT has more than 100 million users, making it the fastest growing consumer application to date.
OpenAI's GPT-4 model is released in March 2023 and is regarded as an impressive improvement over GPT-3.5, with the caveat that GPT-4 retains many of the same problems of the earlier iteration. Unlike previous iterations, GPT-4 is multimodal, allowing image input as well as text. GPT-4 is integrated into ChatGPT as a subscriber service. OpenAI claims that in their own testing the model received a score of 1410 on the SAT (94th percentile),163 on the LSAT (88th percentile), and 298 on the Uniform Bar Exam (90th percentile).
In response to ChatGPT, Google releases in a limited capacity its chatbot Google Bard, based on the LaMDA and PaLM large language models, in March 2023.In May 2023, Google made an announcement regarding Bard's transition from LaMDA to PaLM2, a significantly more advanced language model.
(Source: Wikipedia)
Challenges in the Wake of Opportunities
The adoption of OpenAI and other AI technologies presents several challenges, especially concerning data privacy issues. Here are some of the key challenges related to data privacy when adopting OpenAI or similar AI systems:
Risks Associated with Training Data
The accidental leakage of personally identifiable information (PII) during data inputs for training and prompts in AI models poses a serious threat to data privacy and security. PII includes sensitive information such as names, addresses, contact details, and even financial or medical records, which, if exposed, could lead to identity theft, fraud, or other malicious activities.
As AI models are often trained on vast datasets that may contain PII, there is a risk of unintentionally incorporating this information into the model's learned patterns. Additionally, prompts used to interact with AI models could inadvertently expose PII, further exacerbating the issue. To safeguard against such risks, rigorous data anonymization and de-identification techniques must be employed during the training process, and AI developers and users need to be vigilant about the information they share to protect individuals' privacy and maintain the integrity of AI systems.
Data Access Controls
Data access controls are particularly challenging for AI due to several reasons.
- Firstly, AI models typically require large volumes of diverse data for effective training and performance. This extensive data requirement necessitates access to a wide range of datasets, some of which may contain sensitive or personal information. Ensuring access only to authorized and relevant data is a complex task.
- Secondly, AI models often operate on cloud-based platforms or distributed environments, making it difficult to track and control data access across multiple locations and systems. The data may reside in various databases, and maintaining consistent access controls can become unwieldy.
- Furthermore, AI models tend to learn and improve iteratively by continuously ingesting new data, which can further complicate access control mechanisms. Striking a balance between enabling AI models to learn from fresh data and ensuring data privacy can be quite challenging.
- Finally, AI systems can be vulnerable to attacks targeting data poisoning or adversarial inputs. In such scenarios, controlling data access becomes crucial to prevent malicious data from influencing the model's behavior.
To address these challenges, robust data governance frameworks, access control policies, and data masking techniques like data tokenization must be employed. Implementing such methods can help safeguard sensitive data while still allowing AI models to make meaningful inferences.
Collaboration between AI developers, data scientists, and data owners is essential to establish effective data access controls that prioritize privacy and security while promoting AI advancements. Organizations must prioritize data protection, implement robust security measures, and be transparent with users about data usage and AI model capabilities.
Protecto's Intelligent Data Tokenization Solution
Protecto offers intelligent tokenization to ensure that sanitized data remains machine-readable, enabling companies to harness data-driven insights, predictive analytics, and advanced automation from AI. Using tokenization, companies can leverage the full potential of AI while ensuring privacy and data security.
Here's how Protecto’s Intelligent Tokenization works:
- Input Data Masking:
Protecto masks sensitive data, including PII, before the data is received by the LLM AI system. The data is transformed into a tokenized format, making it incomprehensible and inaccessible to anyone without the necessary permissions.
- Model Training:
The LLM AI model is then trained on the masked data. It learns to understand and process the tokenized information without compromising the original PII.
- Responses with Masked PII:
Since training data was masked before feeding to LLM, during regular interactions with users, none of the responses from the LLM AI will have PII or sensitive data. This means that sensitive information is never exposed to any user without the user having granted explicit permission to access it.
- Controlled Unmasking:
For users who are authorized to access PII, Protecto handles unmasking securely. Only those with proper credentials or permissions can view the original, unmasked PII in the responses from the LLM AI.
Enterprises can confidently adopt AI technologies without worrying about data breaches or accidental leaks. Leverage intelligent tokenization to provide an extra layer of security and protection for your sensitive and personal data.
If your organization is leveraging LLM AI system, and you are worried about how you can protect your personal and sensitive data then schedule a demo or sign up for a free trial today to learn how Protecto can mitigate your privacy and data security risks.

Prevent millions of $ of privacy risks. Learn how.
We take privacy seriously. While we promise not to sell your personal data, we may send product and company updates periodically. You can opt-out or make changes to our communication updates at any time.


